Если нужно добавить несколько разных объектов в сцену, и при этом, каждый объект должен появляться в сцене с большей или меньшей вероятностью, можно воспользоваться методом генерации случайных наборов “random.choice” из модуля “numpy”.

 .blend file on Patreon
.blend file on Patreon
Для начала создадим список объектов, которые нужно добавить в сцену. Пусть это будут сферы, кубы и Сюзанны:
|
1 |
k = ['sphere', 'cube', 'monkey'] |
Также зададим список вероятностей, с которыми данные объекты должны появляться в сцене:
|
1 |
ki = [0.6, 0.3, 0.1] |
Список вероятностей должен содержать такое же количество элементов, как и список объектов. Число соответствует вероятности появления в сцене объекта, находящегося в списке объектов на том же месте.
В нашем случае для сфер вероятность появления равна 0.6 (чаще всего), для кубов – 0.3 (реже) и для Сюзанн – 0.1 (совсем редко).
Конвертируем список вероятностей в массив numpy (numpy.array). Дополнительно проведем нормализацию значений. Она нужна в случае, если сумма заданных нами вероятностей не равна 1 (например, если мы задали вероятности в процентном формате [60, 30, 10]).
|
1 2 3 4 |
import numpy as np p = np.array(ki) p /= p.sum() |
Вызовем метод random.choice, чтобы сгенерировать набор из 6 объектов, которые мы потом добавим в сцену.
|
1 2 3 4 5 6 |
rez = np.random.choice( a=k, size=6, replace=True, # False to make only unique choice p=p ) |
В первом параметре “a” мы указали исходный перечень объектов.
Параметр “size” мы задали равным 6. Это значит, что в результате мы хотим получить список из шести объектов.
Так как количество нужных нам на выходе объектов больше чем в исходном списке, параметр “replace” нужно задать равным True. Это значит, что мы допускаем повторения объектов в результирующем списке. Если установить его равным False, то в результирующем списке каждый объект из исходного списка будет присутствовать только один раз. Однако, в этом случае нужно следить, чтобы в исходном списке объектов было больше или равное заданному в параметре “size” количеству.
В параметре “p” мы указываем список с нормализованными вероятностями.
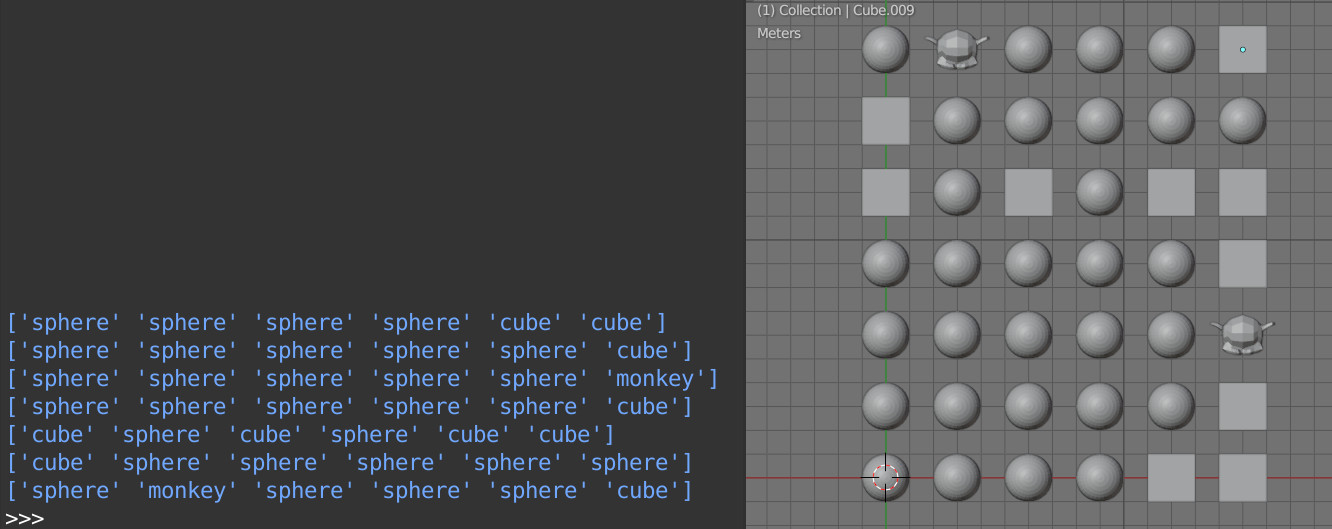
Если выполнить приведенный код несколько раз и вывести полученный список на печать,
|
1 2 3 4 5 6 7 8 9 |
print(rez) # ['sphere' 'sphere' 'sphere' 'sphere' 'cube' 'cube'] # ['sphere' 'sphere' 'sphere' 'sphere' 'sphere' 'cube'] # ['sphere' 'sphere' 'sphere' 'sphere' 'sphere' 'monkey'] # ['sphere' 'sphere' 'sphere' 'sphere' 'sphere' 'cube'] # ['cube' 'sphere' 'cube' 'sphere' 'cube' 'cube'] # ['cube' 'sphere' 'sphere' 'sphere' 'sphere' 'sphere'] # ['sphere' 'monkey' 'sphere' 'sphere' 'sphere' 'cube'] |
то хорошо видно, что сферы в результате встречаются чаще всего, кубы – гораздо реже, а Сюзанны – совсем редко, что и требовалось получить.