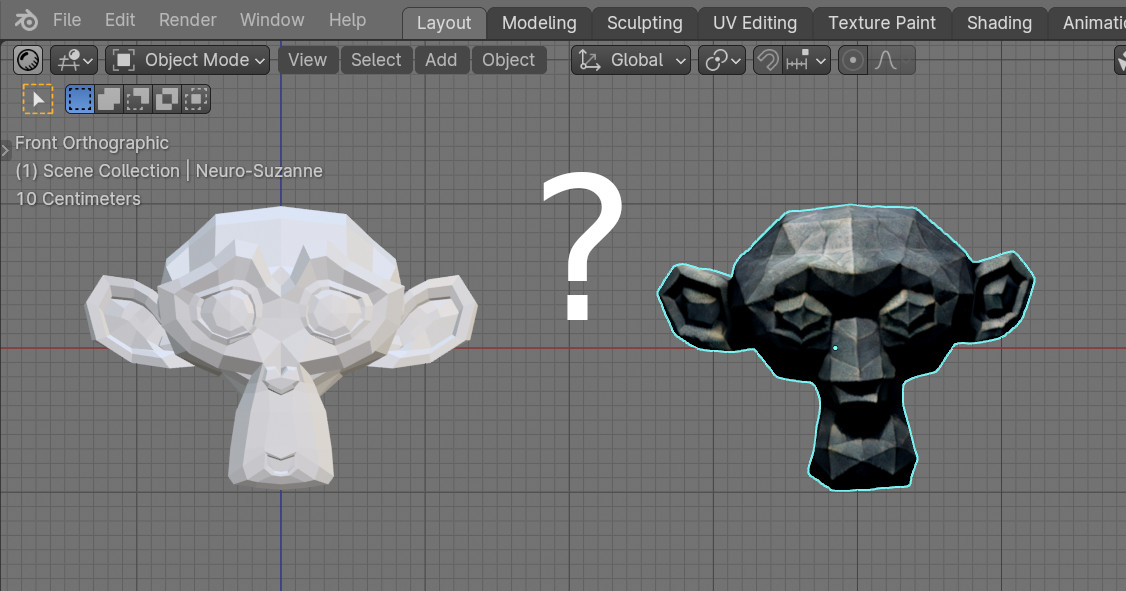
One of the popular directions in the neural networks development currently is the creation of a 3D objects from images. Using a Suzanne’s mesh and its rendered image, we can check how this really works.
 .blend file with neuro-Suzanne on Patreon
.blend file with neuro-Suzanne on Patreon
For researching, we can use any neural network that creates 3D models from a picture. They all work according to the same principle for estimating the depth of the image, and therefore the result for all will be, less or more, the same.
Let’s take Suzanne’s render as the source image. We know what the mesh looks like and its topology, so we can compare what we started with, and what we got when using a neural network.
Through several experiments, together with Vyacheslav Kobozev, the most contrasting render of Suzanne with white background was selected. Looking ahead a little, we can note that when using less contrasting images, the result will be less consistent.

Send image to the neural network.
The neural network, selected for research, first generates a “fast”, rough, 3D model. This generation takes from 5 to 30 minutes.

It can be exported back to Blender using common formats, for example – OBJ.

Switching to edit mode to view the topology, we see an extremely dense mesh consisting of triangles.
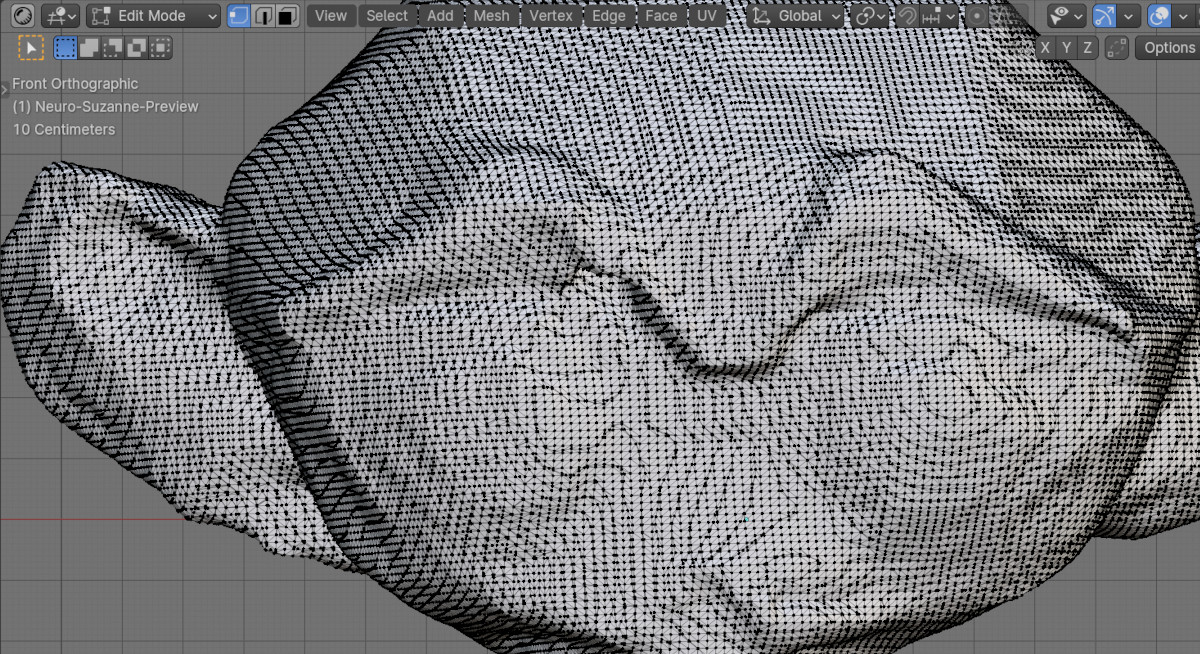
Suzanne’s original mesh consists of 507 vertices and 500 faces.
The mesh created by the neural network has 95544 vertices and 191080 faces.
At the second stage of the neural network’s work, which takes from several hours to several days, the neural network tries to improve the resulting model and make it more consistent with the original image.
The result is the following:
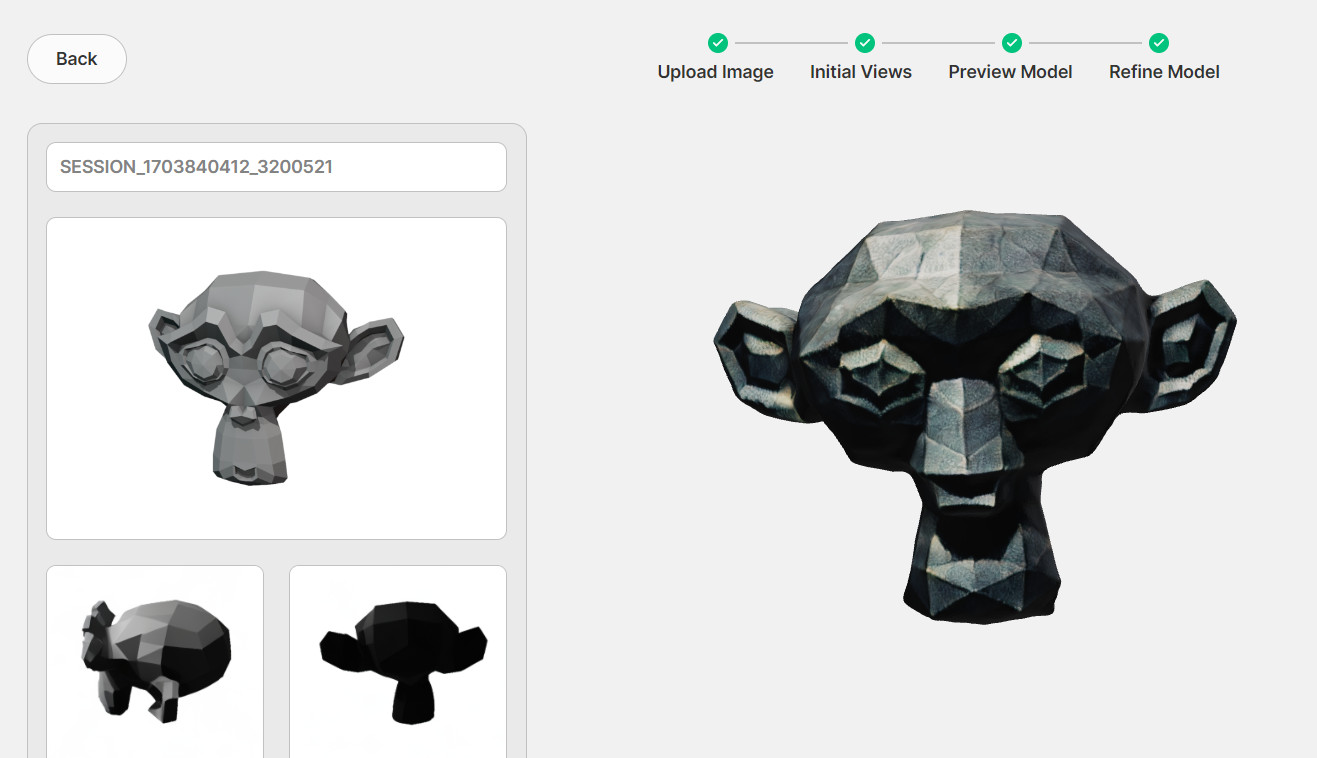
Export the tuned model in OBJ and import it into Blender again.
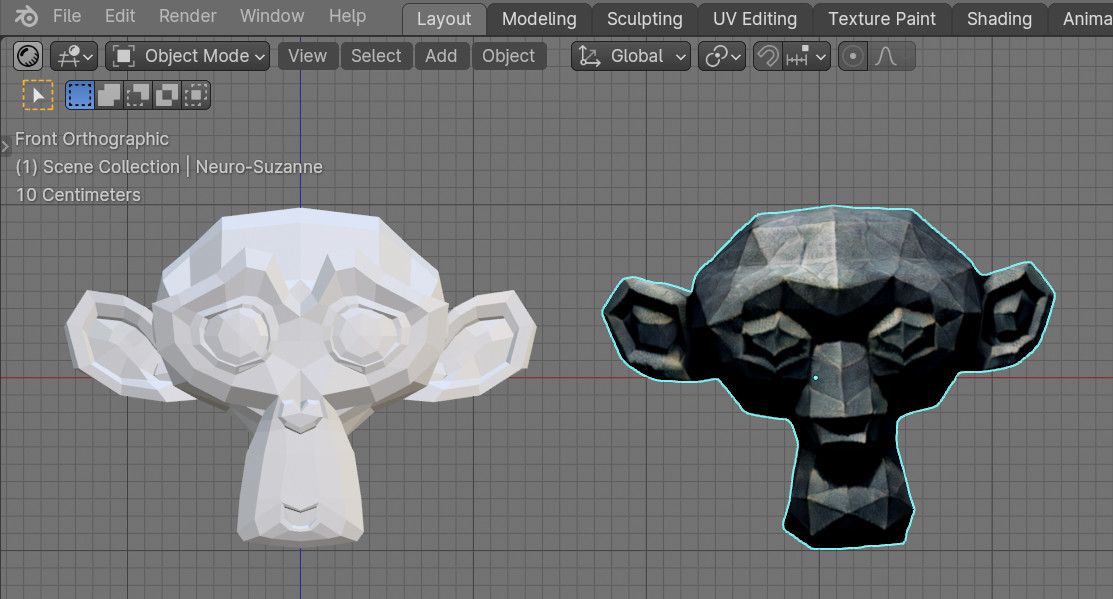
Switch to the edit mode to view the topology.
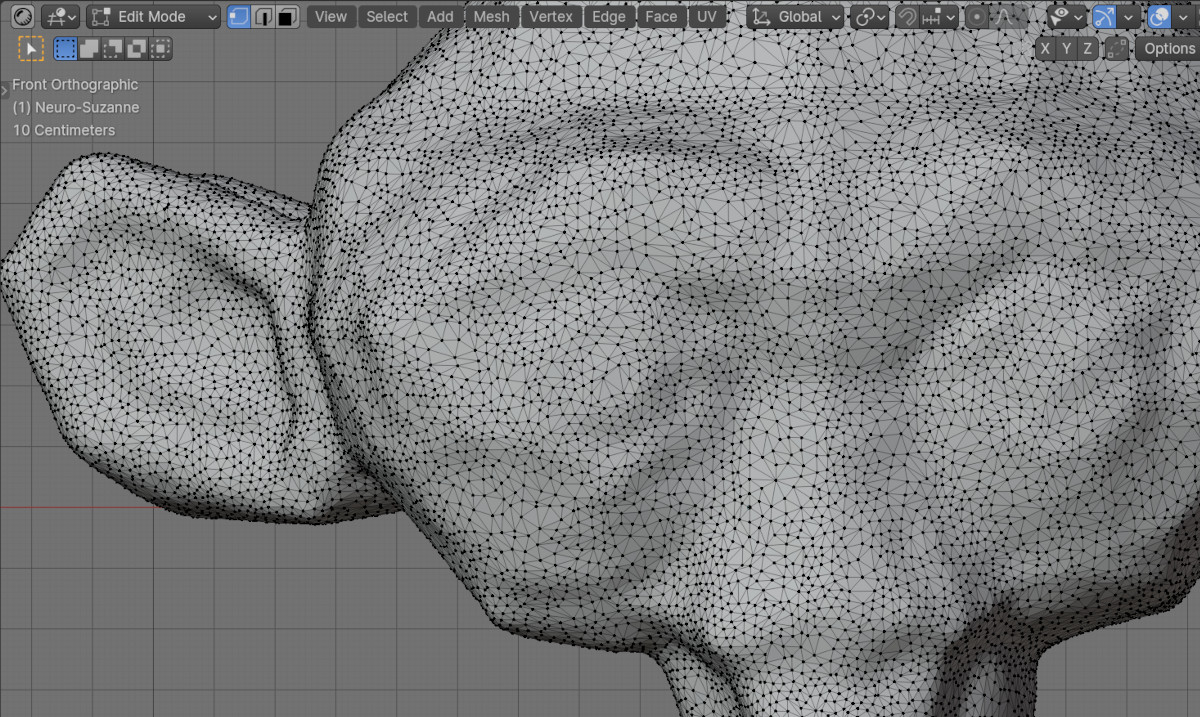
Suzanne’s final mesh from the neural network consists of 25,002 vertices and 50,000 faces.
Based on this simple research, it is not difficult to draw conclusions about how well and efficiently neural networks currently work for converting images into 3D. And about whether neural networks will replace 3D modelers soon.